前言
最近做课设,是一个有关个人隐私安全的课题,在网上找了很多论文,最后上海交通大学的一篇硕士论文《面向社会工程学的SNS分析和挖掘》[1] 给了我很多灵感,因为是对个人隐私安全进行评估,所以我们基于微博社交网络获取的数据进行分析。以下是该系列第一篇文章,记录爬取微博用户信息的过程。
先决条件
我们这次的目标是爬取微博个人用户的资料信息和动态信息并保存在 mysql 数据库中。
因为爬取微博主页 https://weibo.com/ 或者 https://m.weibo.cn/ 较为困难,所以我们爬取 https://weibo.cn,这是一个落后的塞班年代的网页,没有混淆等等一系列新技术,用户动态等从html里面就可以获取,爬取相对来说比较简单。
首先要对网页进行大致分析,获取爬虫的先决条件。
cookies
因为微博对访客进行了限制,所以请求里面没有 cookies 的话动态无法抓取完全。
故我们也需要获取 cookie:
- 用Chrome打开https://passport.weibo.cn/signin/login;
- 按F12键打开Chrome开发者工具;
- 点开“Network”,将“Preserve log”选中,输入微博的用户名、密码,登录
- 点击Chrome开发者工具“Name"列表中的"m.weibo.cn",点击"Headers",其中"Request Headers"下,"Cookie"后的值即为我们要找的cookie值,复制即可
UID
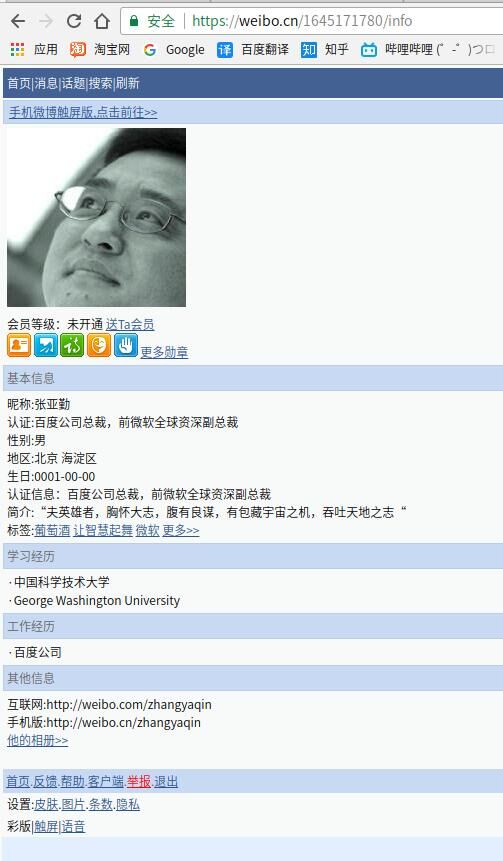
因为我们是抓取用户数据,所以首先应该知道如何获取唯一标识符——uid,每个用户的 uid 是不一样的,有了 uid 我们才可以通过它来标识用户。登录自己的账户以后,我们可以访问用户的资料页(以张亚勤为例),可以看到页面地址为 https://weibo.cn/1645171780/info,其中 "1645171780" 即为张亚勤的 uid,如图所示:
网页分析
获取了 uid 和 cookie ,我们来对网页进行详细分析。
用户资料页源码分析
因为资料页数据量很少,分析和处理都比较容易,所以首先从这里下手。
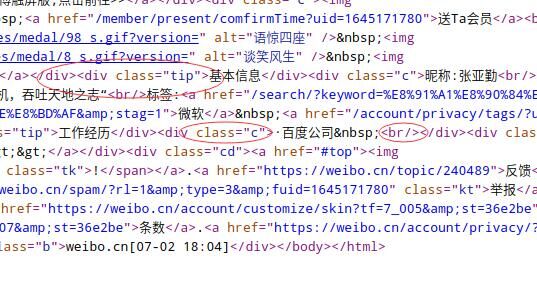
由上一张图片可以看出,资料页分成 基本信息 ,学习经历,工作经历,其他信息 四个模块,我们只需要前三个模块就可以了。分析源码的 html ,我们发现 class="tip"> 刚好可以标识四个信息模块,而对于每个模块内部的资料条目,class="c" 可以进行一一标识,如图所示:
使用正则表达式进行匹配,关于正则表达式的使用方法,请看我的另一篇文章。代码如下:
tip = re.compile(r'class="tip">(.*?)></div>', re.S) #匹配四个模块所有内容 title = re.compile(r'(.*?)</div><div', re.S) # 匹配基本信息/学习经历/工作经历/其他信息 node = re.compile(r'.*?class="c"(.*?)$', re.S) # 匹配一个模块中的所有内容 info = re.compile(r'>(.*?)<br/', re.S) # 匹配资料条
用户动态页源码分析
对于一页的动态来说很好分析,每一条动态内容前面都有 <span class="ctt">,并且一一对应。而动态发布时间一一对应 <span class="ct"> ,如图所示:

正则表达式代码如下:
dynamic = re.compile(r'.*?><span class="ctt">(.*?)<a href', re.S) # 匹配动态 times = re.compile(r'.*?<span class="ct">(.*?) ', re.S) # 匹配动态发布时间
可以从第一页中获取页数:
page_number = re.compile(r'.*/(\d*?)页</div>', re.S) # 匹配动态页数
爬取信息
有了前面的铺垫,爬取用户资料便比较容易实现了。
对于用户资料,使用前面的正则表达式对爬去的页面进行处理,有以下代码:
tip = re.compile(r'class="tip">(.*?)></div>', re.S) #匹配四个模块所有内容 title = re.compile(r'(.*?)</div><div', re.S) # 匹配基本信息/学习经历/工作经历/其他信息 node = re.compile(r'.*?class="c"(.*?)$', re.S) # 匹配一个模块中的所有内容 info = re.compile(r'>(.*?)<br/', re.S) # 匹配资料条 Uname = '' Certified = '' Sex = '' Relationship = '' Area = '' Birthday = '' Education_info = '' Work_info = '' Description = '' for one in tips: titleone = re.findall(title, one) # 信息标题 node_tmp = re.findall(node, one) infos = re.findall(info, node_tmp[0]) # 信息 if (titleone[0] == '基本信息'): for inf in infos: if (inf.startswith('昵称')): _, Uname = inf.split(':', 1) elif (inf.startswith('认证信息')): print(inf) _, Certified = inf.split(':', 1) elif (inf.startswith('性别')): _, Sex = inf.split(':', 1) elif (inf.startswith('感情状况')): _, Relationship = inf.split(':', 1) elif (inf.startswith('地区')): _, Area = inf.split(':', 1) elif (inf.startswith('生日')): _, Birthday = inf.split(':', 1) elif (inf.startswith('简介')): print(inf.split(':')) _, Description = inf.split(':', 1) else: pass elif (titleone[0] == '学习经历'): for inf in infos: Education_info += inf.strip('·').replace(" ", '') + " " elif (titleone[0] == '工作经历'): for inf in infos: Work_info += inf.strip('·').replace(" ", '') + " " else: pass
而对于用户动态信息,处理的代码:
dynamic = re.compile(r'.*?><span class="ctt">(.*?)<a href', re.S) # 匹配动态 times = re.compile(r'.*?<span class="ct">(.*?) ', re.S) # 匹配动态发布时间 page_number = re.compile(r'.*/(\d*?)页</div>', re.S) # 匹配动态页数 dys = re.findall(dynamic, res.text) ts = re.findall(times, res.text) pages = re.findall(page_number, res.text) pagenums = pages[0] mainurl = url label = 0 # 标签用于计数,每5~20次延时10S tag = random.randint(5, 20) for pagenum in range(int(pagenums))[1:]: if (label == tag): time.sleep(10) label = 0 tag = random.randint(5, 20) # 随机选择,防止被ban cookie = random.choice(cookies) cookie = getcookies(cookie) headers = { 'User_Agent': random.choice(user_agents) } pagenum += 1 label += 1 url = mainurl + '?page=' + str(pagenum)#更改页数 page = gethtml(url, headers, cookie, conf, use_proxies) dys += re.findall(dynamic, page.text) ts += re.findall(times, page.text) dys = dys[1:]
至此爬虫这部分代码基本上完成。
保存数据到数据库
如果没有保存在数据库的需要,可以不用阅读该部分。
本来之前是使用 pymysql + SQL语句实现数据库操作,但是这样太繁琐了,并且这些访问数据库的代码如果分散到各个函数中,势必无法维护,也不利于代码复用。所以在这里我使用ORM框架(SQLAlchemy)来操作数据库,该框架实现了对数据库的映射操作,即封装了数据库操作,简化代码逻辑。
首先创建三个表:
# 微博用户信息表 wb_user = Table('wb_user', metadata, Column('user_ID', Integer, primary_key=True, autoincrement=True), # 主键,自动添加 Column("uid", String(20), unique=True, nullable=False), # 微博用户的uid Column("Uname", String(50), nullable=False), # 昵称 Column("Certified", String(50), default='', server_default=''), # 认证信息 Column("Sex", String(200), default='', server_default=''), # 性别nullable=False Column("Relationship", String(20), default='', server_default=''), # 感情状况 Column("Area", String(500), default='', server_default=''), # 地区 Column("Birthday", String(50), default='', server_default=''), # 生日 Column("Education_info", String(300), default='', server_default=''), # 学习经历 Column("Work_info", String(300), default='', server_default=''), # 工作经历 Column("Description", String(2500), default='', server_default=''), # 简介 mysql_charset='utf8mb4' ) # 微博用户动态表 wb_data = Table('wb_data', metadata, Column('data_ID', Integer, primary_key=True, autoincrement=True), # 主键,自动添加 Column('uid', String(20), ForeignKey(wb_user.c.uid), nullable=False), # 外键 Column('weibo_cont', TEXT, default=''), # 微博内容 Column('create_time', String(200), unique=True), # 创建时间,unique用来执行upsert操作,判断冲突 mysql_charset='utf8mb4' ) # 动态主题表 wb_topic = Table('wb_topic', metadata, Column('topic_ID', Integer, primary_key=True, autoincrement=True), # 主键,自动添加 Column('uid', String(20), ForeignKey(wb_user.c.uid), nullable=False), # 外键 Column('topic', Integer, nullable=False), # 主题-----默认5类 Column('topic_cont', String(20), nullable=False, unique=True), # 主题内容 mysql_charset='utf8mb4' )
这里有一个细节需要注意,那就是 mysql 的编码使用了utf8m64的编码方式,为什么要使用这种方式呢?因为微博里面的emoji 表情占4个字节,超过了utf-8 编码范围:UTF-8 是 3 个字节,其中已经包括我们日常能见过的绝大多数字体,但 3 个字节远远不够容纳所有的文字, 所以便有了utf8mb4 , utf8mb4 是 utf8 的超集,占4个字节, 向下兼容utf8。使用 utf8mb4 要求:
MySQL数据库版本>=5.5.3
MySQL-python 版本 >= 1.2.5
然后我们将爬虫获取的信息存到数据库中,首先是资料页数据:
from sqlalchemy import MetaData, Table from sqlalchemy.dialects.mysql import insert ins = insert(table).values(uid=uid, Uname=Uname, Certified=Certified, Sex=Sex, Relationship=Relationship,Area=Area,Birthday=Birthday,Education_info=Education_info,Work_info=Work_info,Description=Description) ins = ins.on_duplicate_key_update( # 如果不存在则插入,存在则更新(upsert操作#http://docs.sqlalchemy.org/en/latest/dialects/mysql.html#mysql-insert-on-duplicate-key-#update) Uname=Uname, Certified=Certified, Sex=Sex, Relationship=Relationship, Area=Area, Birthday=Birthday, Education_info=Education_info, Work_info=Work_info, Description=Description ) conn.execute(ins)
接着是动态数据保存在数据库中:
re_nbsp = re.compile(r' ', re.S) # 去除$nbsp re_html = re.compile(r'</?\w+[^>]*>', re.S) # 去除html标签 re_200b = re.compile(r'\u200b', re.S) # 去除分隔符 re_quot = re.compile(r'"', re.S) for i in range(len(ts)):#len(ts)为动态数 #去除噪声 dys[i] = re_nbsp.sub('', dys[i]) dys[i] = re_html.sub('', dys[i]) dys[i] = re_200b.sub('', dys[i]) dys[i] = re_quot.sub('', dys[i]) ins = insert(table).values(uid=uid, weibo_cont=pymysql.escape_string(dys[i]), create_time=ts[i]) ins = ins.on_duplicate_key_update(weibo_cont=pymysql.escape_string(dys[i])) conn.execute(ins)
尾声
整个爬虫的数据获取部分已经基本上介绍完毕,完整代码见 https://github.com/starFalll/Spider .
下一篇介绍一下对获取的数据进行处理的过程。
参考:[1]陆飞.面向社会工程学的SNS分析和挖掘[D].上海:上海交通大学,2013.