前言
前面 这篇文章 介绍了爬取微博用户资料和动态并将数据保存在数据库的过程。下面来说一下对数据库数据与分析的过程。
数据库分析
首先先来回顾一下前一篇文章中谈到的数据库字段。下图是 weibo 数据库中的三张表:
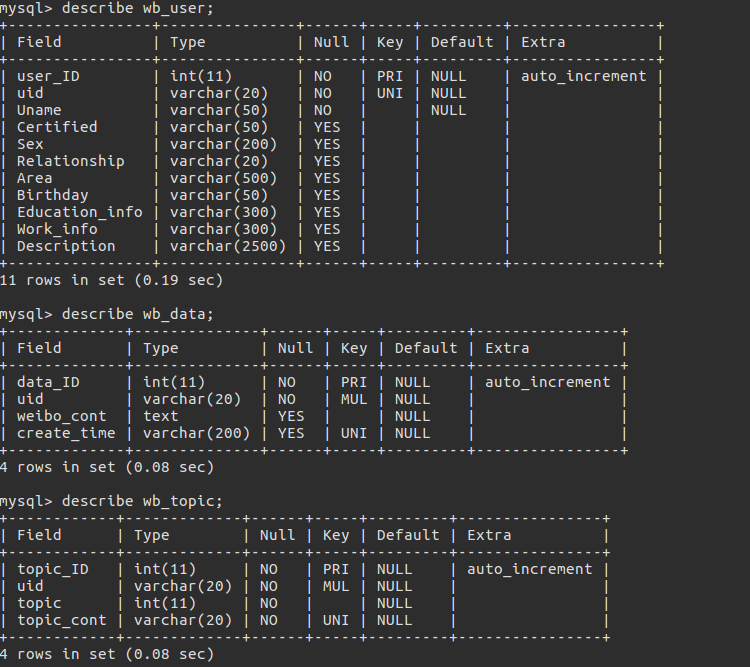
其中每个字段对应的含义请见源码。
再来看一下数据库中每张表里面的内容,首先是用户资料表中的内容:

可以看到和微博资料页的资料是对应的。
再来看看用户动态数据表:

里面包含了用户动态内容和动态发布时间,所以我们首先想到可以对微博动态内容进行处理。
可视化分析
了解了数据库结构以后,我们可以对微博动态和动态发布时间进行可视化处理,在这里,笔者做了以下几点分析:
- 微博动态发布时间处理:画出微博发布时间统计图
- 微博动态简单可视化:词云
- 微博动态词频处理:词频统计以及生成词频图
以上三种分析程序均位于 Data_analysis.py 中, 其 main 函数代码如下:
#可以指定需要分析的用户的uid(必须先存在conf.yaml里面,并且运行了一次爬虫程序) def main(uid): time_lists,str=get_time_str(uid)#将数据库中的微博动态转化为字符串 plot_create_time(time_lists)#画出微博发布时间统计图 with open('data/stop_words.txt') as f: stop_words = f.read().split('\n') str=format_content(str)#去掉表情和一些不必要的符号 word_list=word_segmentation(str,stop_words)#分词并去除停用词 create_wordcloud(word_list) #画出词云 counter = word_frequency(word_list, 10)# 返回前 top_N 个值,如果不指定则返回所有值 print(counter) plot_chart(counter)#会生成词频图保存在weibo_wordfrq.html中
那么这三种分析具体如何实现呢?接下来笔者将对其进行一一阐述。
微博发布时间统计
要对微博动态内容进行可视化分析,第一步是要将微博动态内容整合到一起,下面这段代码是将用户微博中的所有动态拼接到一起,也就是 main 函数里面的第一行代码所调用的函数。
# time_lists,str=get_time_str(uid)# main 函数第一行代码 # 将数据库中的微博动态转化为字符串 def get_time_str(uid): _, engine = Connect('../conf.yaml') # 连接数据库 conn = engine.connect() metadata = MetaData(engine) wb_data = Table('wb_data',metadata, autoload=True) s = select([wb_data]).where(wb_data.c.uid == uid) #从wb_data表中选择uid对应的数据 res = conn.execute(s) conn.close() str = '' time_lists = [] for row in res: str += row[2] + '\n'#拼接动态字段 time_lists.append(row[3]) #将时间转化为列表对象,方便后续处理 return time_lists, str
返回的 time_lists 为动态发布时间列表, str 为所有动态拼接到一起的最终字符串.在这里因为是对时间进行统计,所以我们只需要关注 time_lists 这个列表.先来看看这个列表里面存放的具体内容:
[....,'02月02日 29', '01月21日 30', '01月20日 31', '01月10日 32', '01月02日 33', '01月01日 34', '2017-11-30', '2017-11-29', '2017-11-04', '2017-10-29', '2017-10-27',...]
这是我特意取的一段,刚好两种格式的时间都包含在内。这个列表里面包含的时间是从最近的月份和日期到最初的年份-月份-日期.例如上面的 '2017-11-30' 前面的日期格式均是 XX月XX日XX ,而 '01月01日 34' 后面的同理均是 20XX-XX-XX ,排序方式是由近到远 。在这里,我考虑分析每天发布的微博动态数和时间的变化趋势,并且将时间排列为离现在越远离原点越近。
于是便有了下面这段代码:
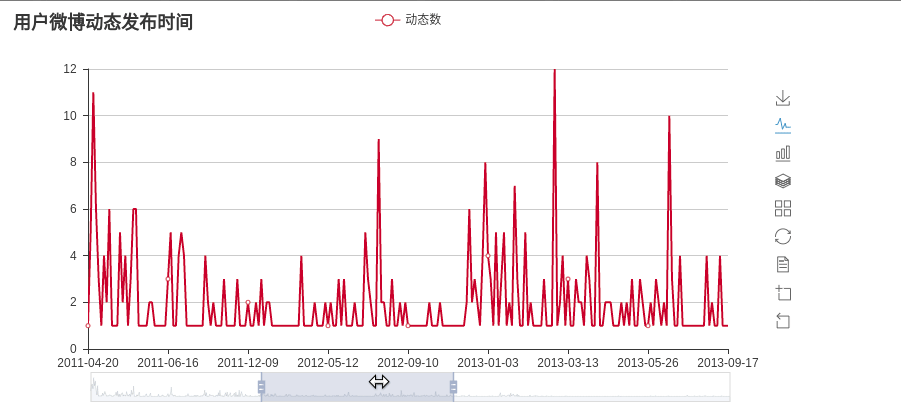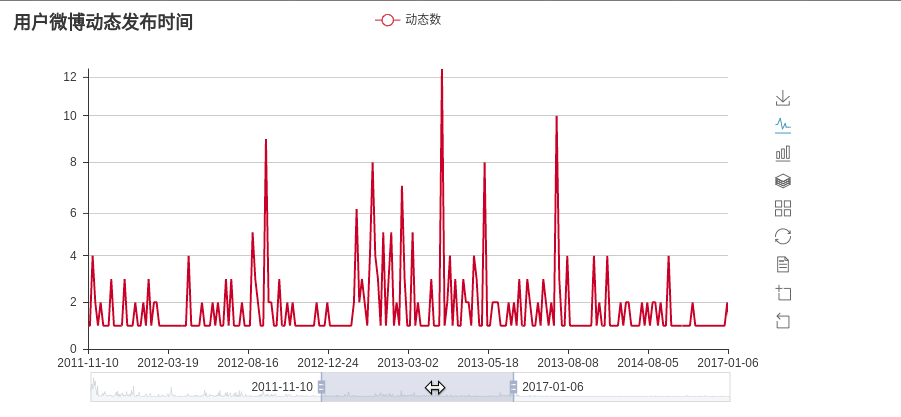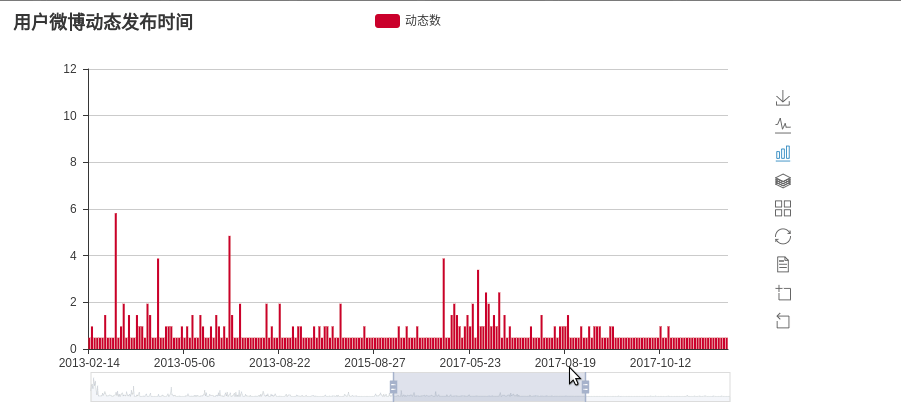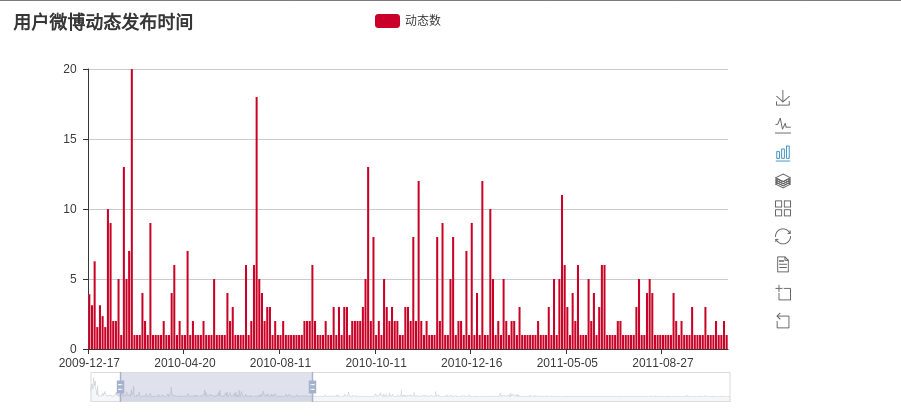
# plot_create_time(time_lists)# main 函数第二行代码 #画出微博发布时间的统计图 def plot_create_time(time_lists): recent_time = re.compile(r'\d{2}月\d{2}日',re.S) long_time = re.compile(r'(\d{4}-\d{2}-\d{2})',re.S) tmp_lists = []#保存**月**日格式的数据 tmp_nums = []#统计**月**日发帖数量 long_lists = []#保存20**-**-**格式的数据 long_nums = []#统计20**-**-**发帖数量 for t in time_lists: res = re.findall(recent_time, t) if(res):#res[0]为**月**日格式的数据 if(not tmp_lists or res[0]!= tmp_lists[-1]):#列表为空或者不与前一个日期重复 tmp_lists.append(res[0]) tmp_nums.append(1) else:#与前一个日期重复,计数加一 tmp_nums[-1]+=1 else:#res[0]20**-**-**格式的数据 res = re.findall(long_time,t) if(not long_lists or res[0]!=long_lists[-1]): long_lists.append(res[0]) long_nums.append(1) else: long_nums[-1]+=1 #将时间按照从远到进的顺序排列 tmp_lists.reverse() tmp_nums.reverse() long_lists.reverse() long_nums.reverse() time_list = long_lists + tmp_lists time_nums = long_nums + tmp_nums #调用 pyecharts 包渲染出统计图 chart = Bar('用户微博动态发布时间') chart.add('动态数', time_list, time_nums, is_more_utils=True,datazoom_range=[10,40],is_datazoom_show=True) chart.render("weibo_dynamic.html")
于是微博发布时间统计图便画出来了,是一个动态的图,效果如下:
词云分析
要对动态内容进行分析,首先要进行分词处理,并且,我们知道常用词语中有很多语气词等,会影响关键词语的权重,所以在进行分析之前需要去掉这些词语,这种词语在信息检索叫做 停用词 。此外,动态中含有的换行符,html代码等不必要的符号也需要去掉。
所以 main 函数中在得到词云之前有下面四行代码:
with open('data/stop_words.txt') as f:#从保存有停用词的文件中读取停用词 stop_words = f.read().split('\n') str=format_content(str)# 去掉表情和一些不必要的符号 word_list=word_segmentation(str,stop_words)#分词并去除停用词
其中调用了 word_segmentation 函数,该函数的内容如下:
# 分词并去除停用词 def word_segmentation(content, stop_words): # 使用 jieba 分词对文本进行分词处理 jieba.enable_parallel() seg_list = jieba.cut(content) seg_list = list(seg_list) # 去除停用词 user_dict = [' ', '哒'] filter_space = lambda w: w not in stop_words and w not in user_dict word_list = list(filter(filter_space, seg_list)) return word_list
在这里,我使用 jieba 进行分词,再对分词结果进行过滤,去除停用词,并返回该分词结果列表。然后使用 word_list 中的数据来画出词云,具体代码如下:
#create_wordcloud(word_list) # main 函数第7行代码 #画出词云 def create_wordcloud(content,image='weibo.jpg',max_words=5000,max_font_size=50): cut_text = " ".join(content) cloud = WordCloud( # 设置字体,不指定就会出现乱码 font_path="HYQiHei-25J.ttf", # 允许最大词汇 max_words=max_words, # 设置背景色 # background_color='white', # 最大号字体 max_font_size=max_font_size ) word_cloud = cloud.generate(cut_text) word_cloud.to_file(image)
最后得到结果 weibo.jpg ,打开看一看:

这就是词云分析的结果,读者可以根据自己需要,比如如果觉得原文和转发出现频率高价值不高可以加入停用词中进行过滤。
词频处理
对微博动态中的词语出现的频率进行统计处理,首先需要词语列表,因为在词云分析中我们已经得到了过滤掉停用词的词语列表 word_list ,所以在这里可以直接拿来使用:
#counter = word_frequency(word_list, 10)# main 函数倒数第三行代码 # 词频统计 # 返回前 top_N 个值,如果不指定则返回所有值 # from collections import Counter def word_frequency(word_list, *top_N): if top_N: counter = Counter(word_list).most_common(top_N[0]) else: counter = Counter(word_list).most_common() return counter
得到的 counter 内容为词语以及出现的次数组成的列表,例如:
[('感觉', 11), ('代码', 10), ('说', 9),('晚上', 9), ('终于', 7), ('麻蛋', 6), ('写', 6), ('数据', 5), ('学校', 5), ('朋友', 4)]
然后根据得到的词频画图并渲染:
# plot_chart(counter)# main 函数最后一行,会生成词频图保存在weibo_wordfrq.html中 #画出词频图,默认为柱状图 def plot_chart(counter, chart_type='Bar'): items = [item[0] for item in counter] values = [item[1] for item in counter] if chart_type == 'Bar': chart = Bar('微博动态词频统计') chart.add('词频', items, values, is_more_utils=True) else: chart = Pie('微博动态词频统计') chart.add('词频', items, values, is_label_show=True, is_more_utils=True) chart.render('weibo_wordfrq.html')
最后得到排名前10位的词语频率统计图:
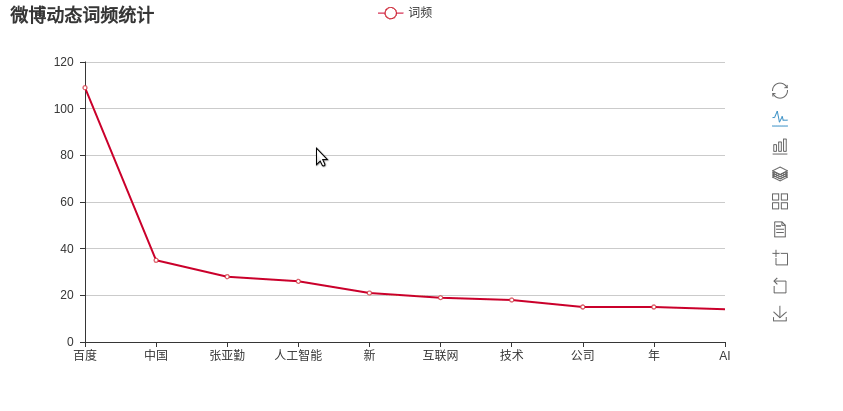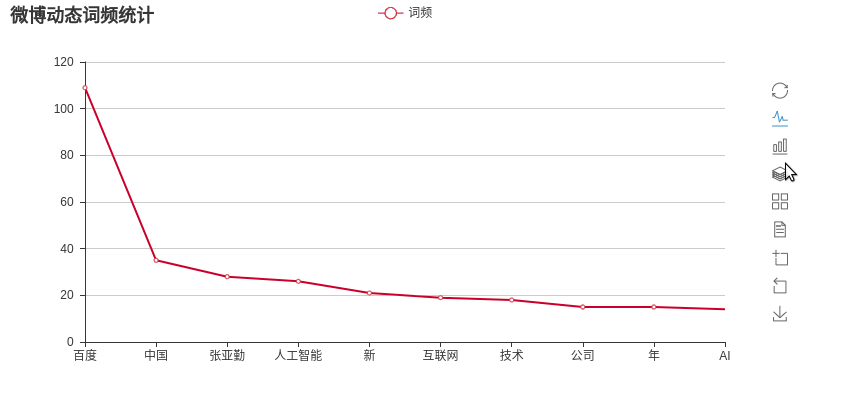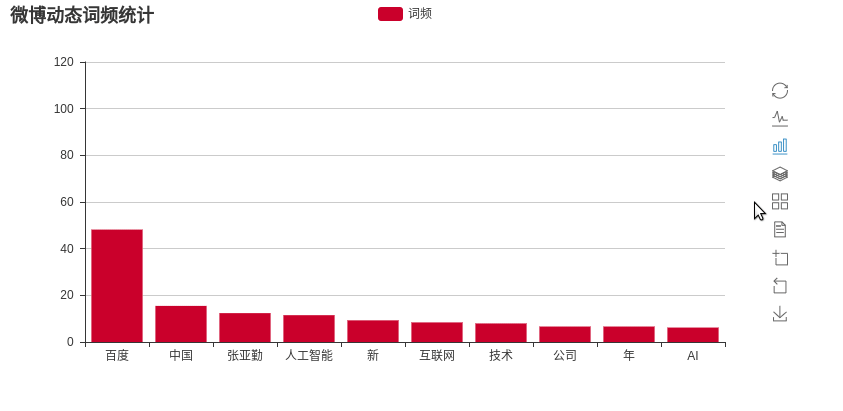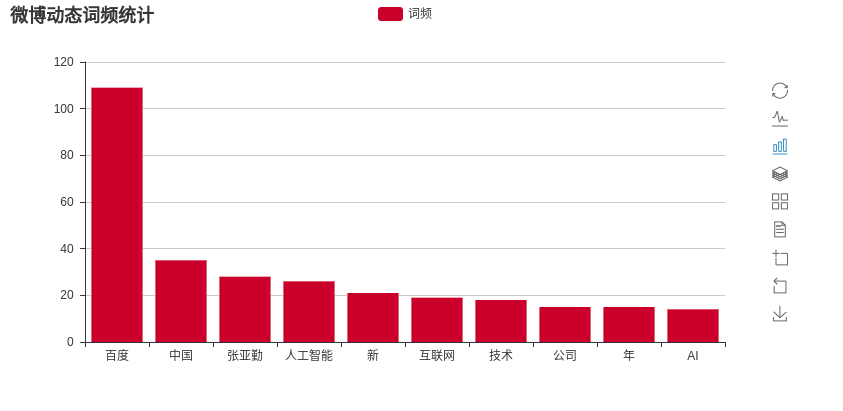
LDA 分析
我们忙活了很久,对用户动态进行了多种分析,但是用户的偏好和个性感觉还是没有把握得很清楚,那么这时候就需要使用一种方法从海量信息中抽取关键部分,最好是能提取出主题,受之前这篇论文[1] 的启发,笔者得知 LDA 便是一种能够满足上述条件的很好的分析方法。
隐含狄利克雷分布(英语:Latent Dirichlet allocation,简称LDA)是一种主题模型,它可以将文档集中每篇文档的主题按照概率分布的形式给出。同时它是一种无监督学习算法,在训练时不需要手工标注的训练集,需要的仅仅是文档集以及指定主题的数量k即可。此外LDA的另一个优点则是,对于每一个主题均可找出一些词语来描述它。
以上说明摘录自维基百科.
本文着眼点在于实践,所以只介绍在 python 中使用 LDA 进行分析的方法,并不阐述 LDA 的原理。更何况,在计算机科学和数据科学的学术讲座中,讲者在介绍到LDA时,都往往会把原理这部分直接跳过去。
该部分代码位于 LDA_Analysis.py ,首先可以看看 main 函数的内容:
def main(uid): wordlists, uid = getwords(uid)#获取分词列表 lda, tf, tf_feature_names, tf_vectorizer = word2vec(wordlists)#将单词转化为向量 Save_Topic_Words(lda, tf_feature_names, uid)#保存主题到数据库 pyLDAvisUI(lda, tf, tf_vectorizer)#根据主题结果进行渲染
第一步便是像之前那样进行分词并过滤停用词,调用了 getwords 函数,代码如下:
#获取微博动态数据 def getwords(uid): _,str = get_time_str(uid) # 将数据库中的微博动态转化为字符串,可以指定uid(conf.yaml里面的) with open('data/stop_words.txt') as f: stop_words = f.read().split('\n') str = format_content(str) word_list = word_segmentation(str, stop_words) # 分词并去除停用词 return word_list,uid
该函数内容和之前介绍的 Data_analysis.py 中的效果一样,故在此不累述。
然后使用 sklearn 机器学习包中自带的 LDA 处理方法进行处理,代码如下:
#lda, tf, tf_feature_names, tf_vectorizer = word2vec(wordlists)# main 函数第二行代码 #使用LDA进行微博动态主题建模与分析 def word2vec(word_list,n_features=1000,topics = 5): tf_vectorizer = CountVectorizer(strip_accents='unicode', max_features=n_features, #stop_words='english',已经进行过停用词处理故不用重复处理 max_df=0.5, min_df=10) tf = tf_vectorizer.fit_transform(word_list) lda = LatentDirichletAllocation(n_components=topics,#主题数 learning_method='batch', #样本量不大只是用来学习的话用"batch"比较好,这样可以少很多参数要调 ) #用变分贝叶斯方法训练模型 lda.fit(tf) #依次输出每个主题的关键词表 tf_feature_names = tf_vectorizer.get_feature_names() return lda,tf,tf_feature_names,tf_vectorizer #返回模型以及主题的关键词表
最后我们将主题以可视化结果展现出来:
#pyLDAvisUI(lda, tf, tf_vectorizer) # main 函数中最后一行 #将主题以可视化结果展现出来 def pyLDAvisUI(lda,tf,tf_vectorizer): page = pyLDAvis.sklearn.prepare(lda, tf, tf_vectorizer) pyLDAvis.save_html(page, 'lda.html') #将主题可视化数据保存为html文件
得到 lda.html ,为渲染以后的结果:
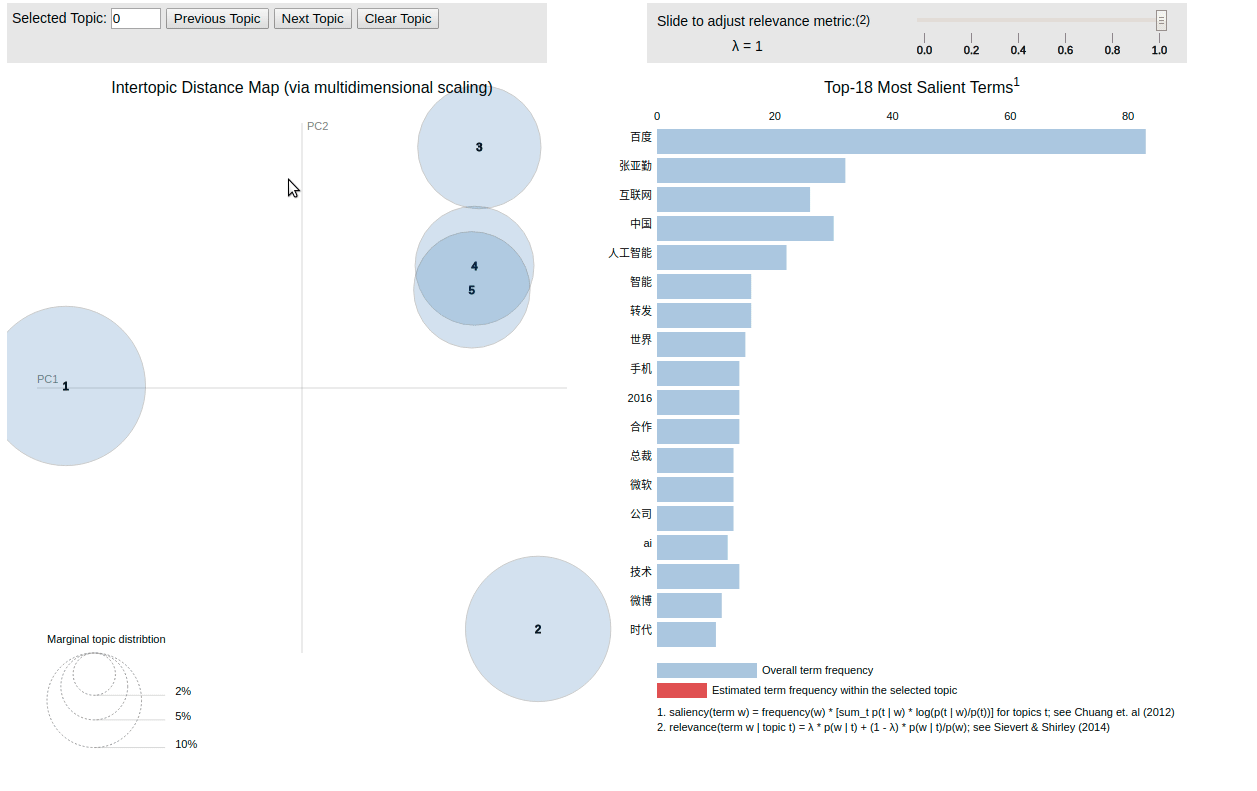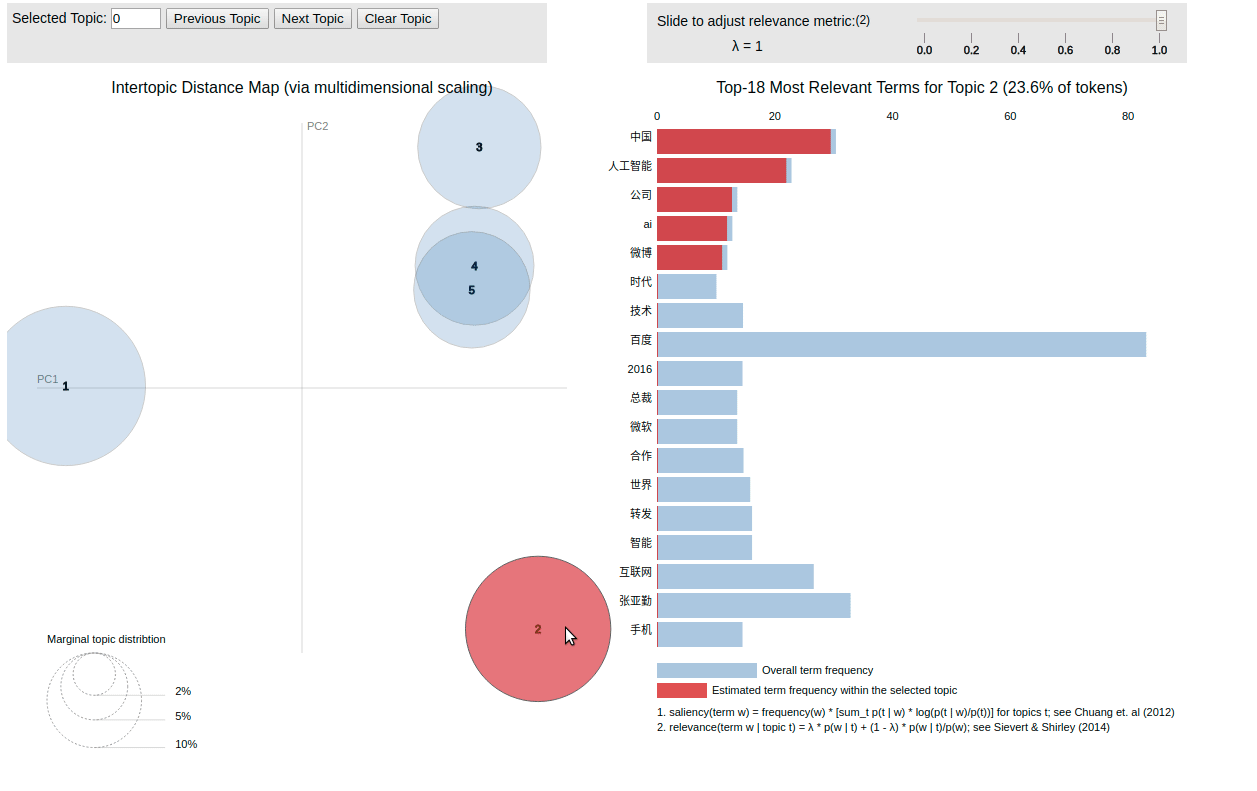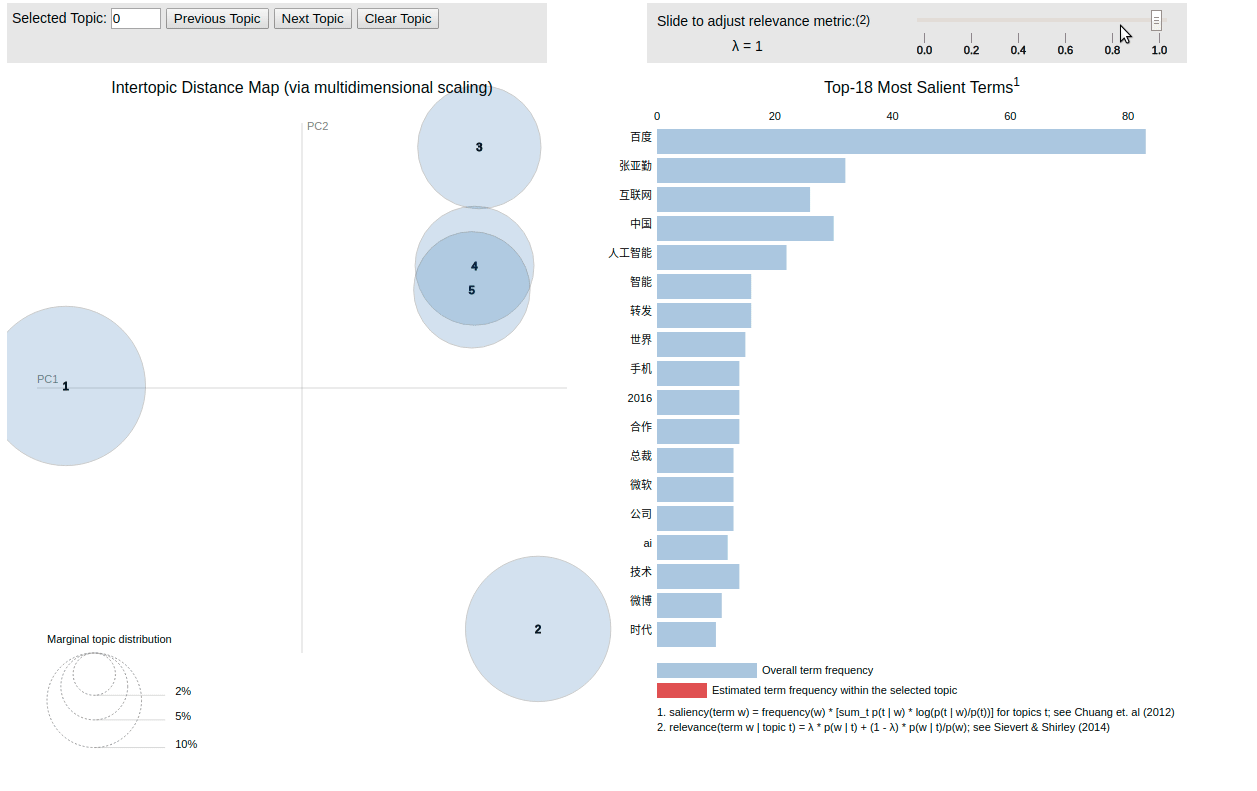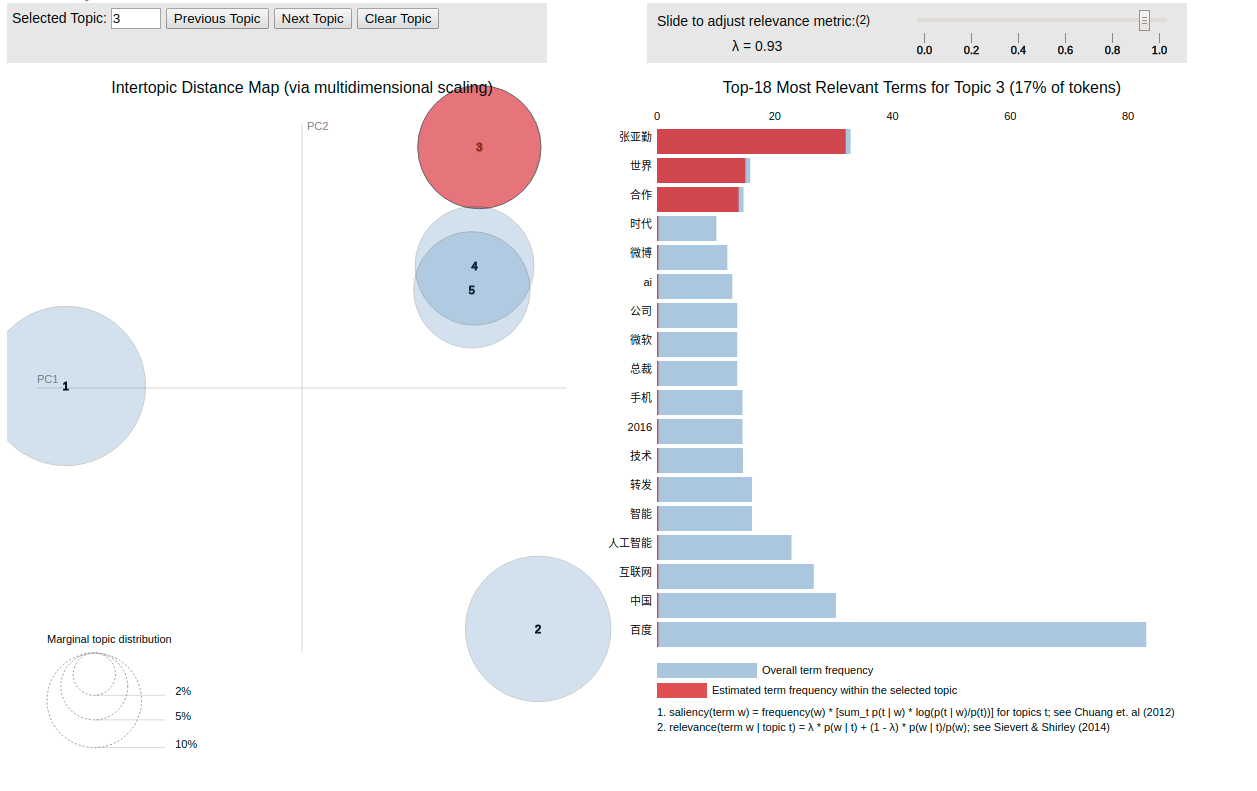
至此,用户信息分析介绍结束。
源码地址:https://github.com/starFalll/Spider
参考:[1]陆飞.面向社会工程学的SNS分析和挖掘[D].上海:上海交通大学,2013.